By Sebastian Bergmann Tillner Jensen, Malene Klarborg Holst, Tine Randrup-Thomsen, Camilla Erfurt Brøchner, & Jonas Kristoffer Lindeløv (supervisor). Project conducted as part of the Psychology bachelor at Aalborg University, Denmark.
Can we frame learning situations in such a way that people actually improve their abilities outside the classroom? We believe that the answer could be yes. Following newer school trends in adopting visible learning, as proposed by Professor of Education John Hattie, we believe that an instruction which motivates the pupil to think outside the box and evaluate the general applicability of their skills might be the key in improving learning. But how do we grab this concept from rich real-life situations and move it into the lab?
Spoiler alert: it involves torturing 52 participants with a quad N back task. The experiment, data, and analysis script is here. Read on…

Where do these crazy thoughts come from?
The holy grail in all of teaching is the transfer of learning, i.e., using a narrow teaching material to achieve generalized effects. Transfer of learning was first introduced by Edward Thorndike, Father of Educational Psychology, in 1901 and after many years of research, it is still a hotly debated topic to what extent humans (and other animals) actually can transfer learning.
In 2008 Jaeggi and colleagues published an article in one extreme of this debate, suggesting the ultimate far transfer: training an N-back task led to large improvements in fluid intelligence. Not surprisingly, this attracted a lot of attention to the N-back task as a holy grail of transfer research – at least in the four years until several large RCTs failed to replicate the findings (Redick et al., 2013, Chooi & Thompson, 2012; see also recent meta-analyses by Melby-Lervåg, Redick & Hulme, 2016 and Soveri et al., 2017).
Put shortly, during the N-back task the participant is presented with a sequence of stimuli, and the task is to decide for each stimulus whether it is the same as the one presented N trials earlier. Try it out yourself: http://brainscale.net/dual-n-back/training.
Entering the lab
Using different versions of the N-back in a pretest-training-posttest design, we created a setup, which allowed us to utilize improvement as a measure of transfer. We split our participants into two identical groups – except we gave them different instructions before the training session: One group received an instruction, based on visible learning, to use the training to improve on the transfer tasks; and the other was directly instructed to improve as much as possible during the training.
Before revealing the shocking nature of the quad N-back, we first need to dig deeper into the N-back…
Are all N-backs the same?
If you have ever stumbled upon the N-back before, it has probably been used as a measure of working memory (WM). But does the N-back live up to the task of encapsulating the rich nature of WM? We say no…
Strong evidence points towards the fact that N-back does not transfer to other WM tasks (i.e. complex span, see Redick & Lindsey, 2013) since it primarily taps into updating and interference control.
But wait! There is more… Evidence points towards the notion that the N-back does not always transfer to other versions of itself!

Research on the holy grail of learning is primarily focusing on 2-backs or higher; meaning that updating and mental reallocation of stimuli is a given. But what if we reduce the amount of N to 1? (see Chen, Mitra & Schlaghecken, 2008).
Creating an N-back transfer spectrum
And now what we have all been waiting for… *drumroll*… The quad N-back! Assuming that transfer varies between different versions of the N-back we can change the number of stimuli used, the type of stimuli used as well as N to create a transfer spectrum ranging from near to far relative to the training task. Disclaimer: This has been done relatively blind-sighted, since we found little literature to lean on, but here we go anyways!
Our shot at a transfer spectrum is visualized on the table below, in which the “farness” is based on the number of stimuli similar to the training task – a dual 2-back with position and audio. Pre- and posttest consisted of five different N-backs as can be seen in the table below.
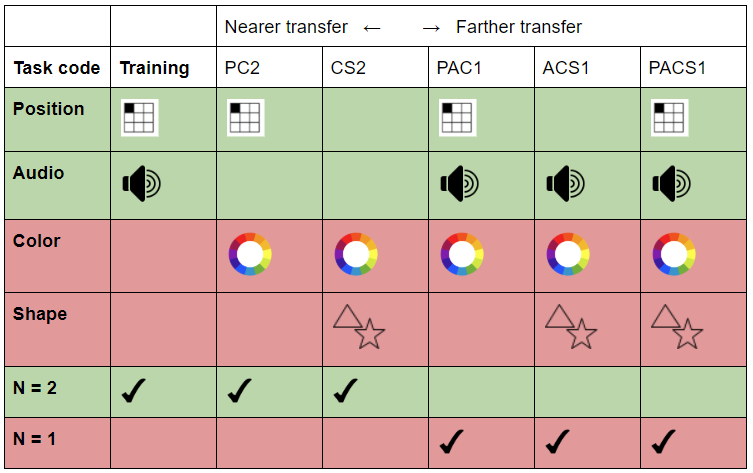
Now you may wonder what a quad 1-back looks like. Lo and behold the actually-not-so-terrifying abomination, which is the quad 1-back. Press the four arrows when the feature is identical to the previous stimuli:
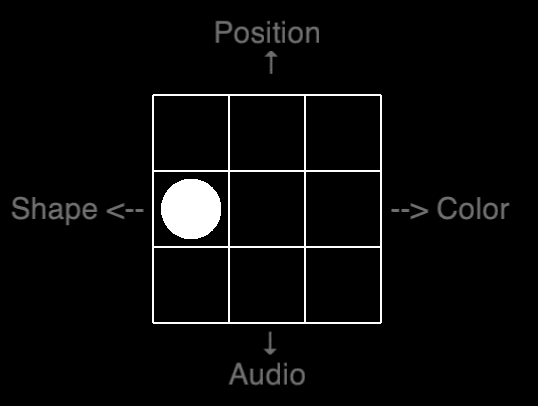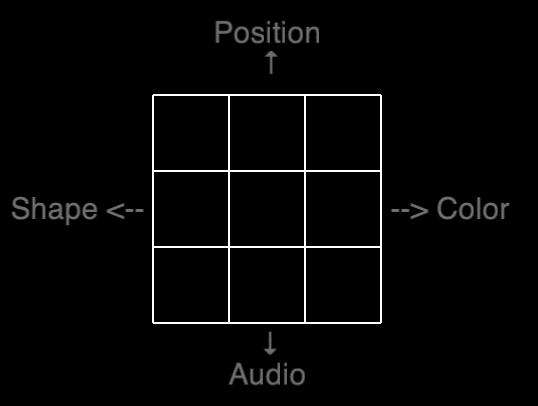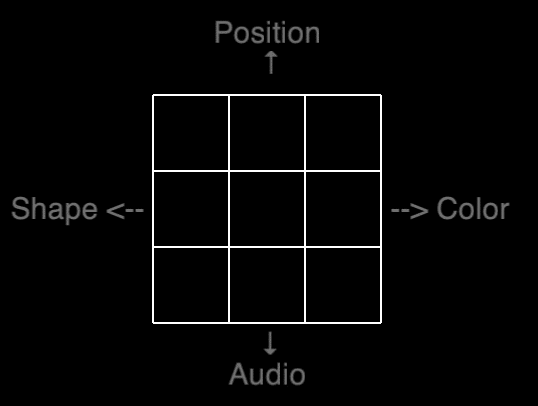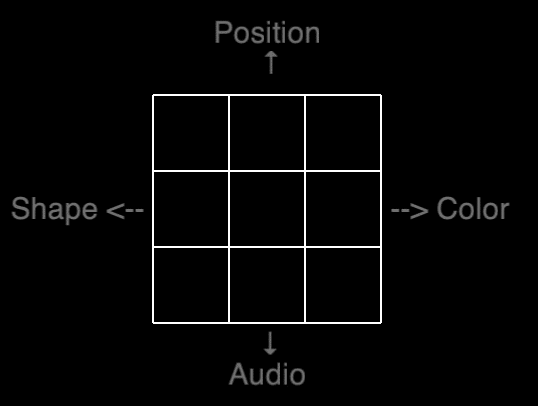
If you are eager to torture yourself with our 1-hour test, you can download our script uploaded here and run it in PsychoPy.
FUN FACT: Our participants actually performed better on the quad 1-back tasks than on the dual 2-back tasks, indicating that we in the future quite ethically can expose our participants to even more stimuli *maniacal laughter*.
If you’re interested in knowing what our data showed, feel free to read the results-section below, and if you’re really, really interested, you can download our full report (in Danish – Google translate is your friend).
Results
We used the BayesFactor R package with default priors. Using default priors is generally not advisable, but this is a student project with a tight timeframe!
As expected, the improvement was quite small during the 10 minutes of training (Δd’ = 0.30 and 0.31 respectively, joint 95% CI [0.05, 0.59]) as revealed by linear regression on the time x instruction interaction. Surprisingly (to us at least), the evidence favored the model that participants who were instructed to focus on the transfer tasks improved just as much as participants who focused on improving on the training (BF01 = 5.1).
Participants who were instructed to focus on transfer had numerically superior improvements in the “nearer” part of the transfer spectrum, but the instruction x task x time interaction in an RM-ANOVA favored the model that the transfer instruction did not cause a superior (different) transfer effect (BF01 = 23.3).
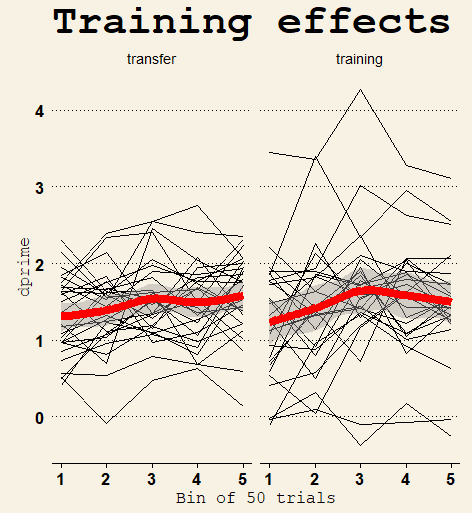
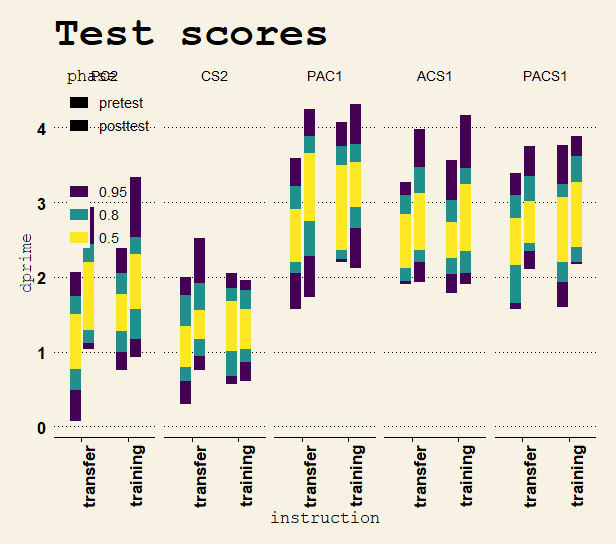
Limitations
We used the same test order in pre- and posttest for all participants, likely imposing order effects (which is basically transfer occurring in between tasks in the pretest). As a solution for future studies we suggest to counterbalance the order of task 1 to 5 in pre- and posttest. Another solution could be to create a baseline score in practice-tasks before continuing to the pretest.
Secondly, our transfer spectrum is not self-evidently correctly ordered. We did not take the difference between 1- and 2-backs into consideration when creating the transfer spectrum, as to why we propose future research to choose between the two. One could focus on only the amount of stimuli instead of both the number of stimuli and N-backs.
Thirdly, we did not have enough participants to establish the desired power level. Further, the training session was probably too short. The obvious solution is to collect more participants and prolong the training.