Du kan sætte et markant aftryk på verden ved at donere på den samme måde, som du investerer. Læg følelser og intuitioner til side og se i stedet velgørenhed som maksimering af return-on-investment. “Velgørenheds-return” er vores medmenneskers liv og velvære.
Med dette approach opdager man en række meget omkostningseffektive men oversete organisationer, der giver 10-100 gange mere for pengene.
Artikelserie
Jeg har skrevet en serie posts om denne tilgang til velgørenhed:
Sundhedsforebyggelse giver vækst – akutte kriser er dyre. Lige nu er det uhyre effektivt at masse-forebygge sundhed i verdens fattigste lande. Det redder liv, forhindrer sygdom, øger skolegang, sikrer familieplanlægning og forbedrer nationaløkonomi.
Det grundlæggende problem er, at meget få kender til disse muligheder, fordi få taler om velgørenhed. Din største impact kan derfor være at tale åbent om, hvor du donerer.
Der er economies of scale inden for velgørenhed. De bedste organisationer i verden er hyper-skalerbare. Case in point er Against Malaria Foundation, der uddeler myggenet mod malaria. Det koster blot omkring 48 kroner at beskytte en familie mod malaria i 2-3 år – alt inklusive. Sidste år uddelte de ca. 17 millioner myggenet. Det har de gjort med kun 13 fastansatte.
Malaria er et stort og forudsigeligt problem og har været det i årtier. Derfor er det muligt at optimere løsningen, bl.a. fordi læringer kan overføres 1-til-1 til næste malariasæson. Vi har robust evidens for effekten af myggenet på død og sygdomsforløb (se fx denne Cochrane meta-analyse på 275.793 personer).
Men dertil har vi også robust evidens for, at det er en omkostningseffektiv måde at sikre mere skolegang, bedre familieplanlægning og at øge den nationaløkonomiske vækst. I forhold til skolegang er sygdomsforebyggende tiltag oftest mere omkostningseffektive end fx flere undervisere, bedre lærebøger, mm.
I den modsatte ende af effektivitets-skalaen har vi akutte kriser som fx (borger)krig og naturkatastrofer. Der er mange faktorer der fordyrer denne type arbejde:
De er uforudsigelige, men kræver hurtig handling. Derfor flyves højtlønnede arbejdere ind frem for at opbygge kompetencen lokalt.
Dårlig infrastruktur og sikkerhed vanskeliggør (fordyrer) arbejdet.
De er ofte langt dyrere at udbedre en skade end at forebygge den.
Pga. unikke politiske/demografiske/geografiske forhold, er det vanskeligere at overføre læringer mellem hver indsats.
Alt dette gør det vanskeligere at opskalere eller lave cost-down forbedringer.
For hver person man kunne hjælpe i kriseområder, har man en fantastisk mulighed for at hjælpe langt flere, fx via myggenet. Men det er de “dyre” indsatser, som organisationerne rykker ud med i vores postkasser, telemarketing, facere og landsindsamlinger.
I de tidligere artikler i denne serie, har jeg talt for, at du bør sætte tal på effektiviteten af en velgørende organisation, før du donerer. Desværre ser mange først og fremmest på administrationsomkostninger. Jeg mener, at administration er en Vanity Metric:
Her er en direkte analogi: Når du køber en smartphone, er du så mest optaget af om du får et godt produkt til prisen (omkostningseffektivitet), eller hvor stor en del der går til producentens administration?
Det samme gælder velgørenhed. Det er i sidste ende real-world effekten der tæller. Lad det være op til organisationen at vurdere, hvor meget administration det kræver at give dig mest velgørenhed per krone, du donerer.
Når du køber en smartphone kan det være en god idé at læse reviews af uafhængige eksperter, der har større kendskab til domænet. De kan skelne skidt fra kanel. Det samme gælder inden for velgørenhed. På https://giveffektivt.dk kan du se en liste over de bedste velgørende formål netop nu.
I Nigeria er GDP per capital ca. $2.000. Men Against Malaria Foundation kan opnå 1 DALY i Nigeria for ca. $50. Deres omkostningseffektivitet ville altså blive ligestillet med en organisation, der er 40 gange mindre effektiv – begge ville få scoren “100%”. Jeg anbefaler i stedet https://www.givewell.org, som går mere i dybden med hver organisation og gør deres vurderinger offentligt tilgængelige. Se fx GiveWells vurdering af Against Malaria Foundation.
Lad mig illustrere hvordan velgørenhedsmarkedet ser ud gennem en investors briller.
Marked A og marked B
Forestil dig, at du kan starte en virksomhed i et af to forskellige markeder. Du er lige kompetent i begge markeder og det kræver den samme indsats. Marked A består af højt specialiserede og relativt ukendte organisationer. Din forventede profit margin er 40% men ingen af dine kolleger investerer i dette marked. Marked B består af store og kendte generalist-organisationer. Din forventede profit margin er blot 2%. Dine kolleger investerer også i marked B og roser dig for at gøre det samme.
Inden for velgørenhed vælger næsten alle donorer desværre at lægge deres penge i marked B – de store og velkendte organisationer (ingen nævnt; ingen glemt). Pengene gør en positiv forskel, men opportunity cost ved ikke at investere i marked A er enorm. Et nyligt estimat er, at de bedste velgørende organisationer opnår 100 gange mere for pengene end de typiske organisationer. Alene blandt verdens mest effektive organisationer er der ca. 10 gange forskel.
Med andre ord vælger mange donorer at hjælpe 1 menneske, uvidende om at de kunne hjælpe 100 mennesker for det samme beløb.
Sådan vælger du marked A
Det grundlæggende problem er, at meget få kender til disse muligheder, fordi få taler om velgørenhed. Din største impact kan derfor være at tale åbent om, hvor du donerer.
Velgørenhed er et slags marked. Alene i Danmark er der et udbud af over 1200 velgørende organisationer som alle kan omsætte dine penge til velgørenhed. Desværre er velgørenhedsmarkedet primært reguleret af, hvor mange følelser det kan vække hos donoren – ikke hvor meget “return” der faktisk er for modtagerne.
Årsagen er ganske enkel: i klassiske udvekslinger, er køber og modtager den samme person. Det regulerer markedet, da du stopper med at købe dårlige produkter og køber flere gode produkter.
Men for velgørenhed er modtageren ikke dig selv. Du mærker altså ikke, om din donation omsættes til flest reddede liv eller mest livskvalitet. Det eneste “produkt” du får, er de gode historier og mavefornemmelser fra den velgørende organisations informationsmaterialer. Derfor får organisationer langt flere donationer ved at optimere for donor-samvittighed (personlige historier fra akutte kriser; sult; krig; osv.) frem for at optimere for effekt. Markedet er bogstaveligt talt ikke effektivt.
Udnyt det ineffektive marked: donér effektivt
Ikke overraskende betyder det ineffektive “velgørenhedsmarked”, at der er voldsomt stor forskel på hvilken effekt din donation skaber. De fleste tror, at der kun er omkring 2 gange forskel i effekten, men det er nærmere 10-100x (Caviola et al., 2020). Du kan altså gøre en langt større forskel, alene ved at vælge den rigtige organisation.
For at gøre det lettest muligt, har jeg været med til at starte https://giveffektivt.dk. Giv Effektivt omsætter hver krone til flest mulige reddede liv og mest mulig livskvalitet. Forhåbentlig kan det være med til at genoprette en efterspørgsel på effekt.
Working with POSIXct objects in R can be slow. To floor a million timestamps down to the nearest quarter-of-hour takes ~7 seconds on my laptop using the usual functions: lubridate::floor_date() and clock::date_floor().
Here is a base R function that achieves the same result in 10 ms:
The job package is on CRAN and judging from the absence of bug-reports, it seems to be doing well! It runs code as an RStudio job, so your console is free in the meantime. It’s very useful to stay productive while doing cross-validation, bayesian MCMC-based inference, etc.
… and then it returns the results to your main session when it’s done (fit, in this case). You can launch multiple jobs and keep track of them in RStudio’s “jobs” pane:
job::job() doing it’s thing!
Check out the job website to read more use cases and the many options for customizing the call.
I have a hobby. I like citing papers that provide strong evidence that is directly in opposition to what the authors claim. Lucky me, because PNAS just published a paper that fits snuggly into this category. It’s titled “Experienced well-being rises with income, even above $75,000 per year”. An even better title would have been “Income is a poor gauge for well-being; don’t bother”.
This is the central figure:
Whoa! The paper doesn’t fail to mention (multiple times) how this is virtually a perfect linear relationship between well-being and log(income). The authors conclude that people with higher income are more satisfied with life and experience more well-being!
The real-life version of this graph
Let’s see what this graph looks like with a linear x-axis and with simulated raw data (see code below). The black dots are simulated individual participants from the study, assuming that statistical assumptions are met. Their exact distribution along the x-axis is not known (the author did not publish raw data), but that doesn’t matter. It only matters how the dots are dispersed for a given income.
You are one of the black dots. You could be one of the other black dots. But income does virtually nothing to lower or improve people’s well-being or life satisfaction. Income explained 1.5% and 4% of the variance in Well-Being and Life Satisfaction respectively (see code below).
Income explained 1.5% and 4% of the variance in Well-Being and Life Satisfaction respectively
Extreme income rise = extreme happiness?
Let’s study the most extreme case: you have an annual income of just $15,000. But now you get to jump into the life of a rich person all the way to the other side of the (linear) graph with an annual income of $480,000. The result of this 32-fold increase in income is expected to be:
Life Satisfaction: 62% used to rate higher than you. Now only 35% does! But there’s a 24% chance that you will be less happy than before.
Experienced Well-Being: 58% used to rate higher than you. Now only 40% does! But there’s a 33% chance that you will be less happy than before.
Hmm, hardly the extreme happiness rush that one might expect would expect from reading the paper and the ensuing media coverage. It’s a vanishingly small effect, considering the extremeness of this example.
Conclusion
I think it’s fairer to say that we’ve now learned that this paper is solid evidence that income is a really poor gauge for happiness. Someone once wrote a song about this:
Computing quantiles and probability of deterioration is simple. The z-score is your score relative to the whole population in units of standard deviations. So just the results for Life Satisfaction were obtained by reading off the extremes of the graph and computing the associated quantiles in R: pnorm(-0.3) and pnorm(0.4). Probability of negative income change is then just pnorm(-0.3, 0.4).
The plots are fairly straightforward too. First, let’s simulate the raw data:
# Data
N = 33391 # Number of participants
incomes = exp(seq(log(15000), log(480000), length.out = N)) # x-axis of Figure 1
trend_wb = seq(-0.2, 0.25, length.out = N) # Linear, read off Figure 1
trend_ls = seq(-0.3, 0.4, length.out = N) # Linear, read off Figure 1
z_wb = rnorm(N, trend_wb) # z-score is standard normal
z_ls = rnorm(N, trend_ls) # z-score is standard normal
# Merge the data in long format
df = data.frame(
incomes,
z = c(rnorm(N, z_wb), rnorm(N, z_ls)),
outcome = c(rep("Experienced Well-Being", N), rep("Life Satisfaction", N))
)
If you want to verify other results, you can fit the linear models to the (simulated) data and see that we can approximately replicate the r-values reported in the paper (r = 0.17 and r = 0.09) and that this correspond to 4% and 1.5% variance explained, respectively:
I leave it as an exercise to the reader to filter out nonlow_incomes = incomes[incomes > 30000] and assess the predictive performance (lm(z_ls ~ log(nonlow_incomes)).
I’ve made an R package, and I’m happy to report that it is likely to arrive on CRAN before Christmas! The last CRAN review asked me to change a comma, so the outlook is good.
mcp has grown quite ambitious and I think it now qualifies as a general-purpose package to analyze change points, superseding the other change point packages in most aspects. You can read a lot more about mcp in the extensive documentation at the mcp website.
This Twitter thread is a more bite-sized introduction:
Working on an R package `mcp` to infer Multiple Change Points. Good progress yesterday:
mcp is the consequence of a long sequence of events:
Looking at Complex Span data from a large project I did with researchers from Aarhus University, I saw strong performance discontinuities at a single-person level.
I then learned that performance discontinuities play an important role in the estimation of (human) working memory capacity.
I then learned that people mostly use ad-hoc methods to extract such points, including eye-balling graphs. That made me nervous.
I then remembered a very small example from the book Bayesian Cognitive Modeling on inferring change points. I remember it because I was puzzled that Gibbs samplers could sample such points effectively.
I then applied this to a Poisson model of our data and it worked beautifully. It outperformed all other models of this data.
Around here was the first time I looked for other R packages to identify change points. There are a lot of them, but none could handle the hierarchical model I needed and most of them yielded point estimates rather than posteriors.
As I began writing a paper, decided to apply the model to subitizing as well. However, while subitizing accuracy has a single change point, subitizing reaction times seem to have two or three.
I implemented a three-change-points model, and immediately saw how easy it would be to extend it to N change points. That took around a day. That was the time of the first tweet above.
Without much forethought, I took a brief look into R packages, pkgdown, etc., and before I knew it, it became a package.
I began to see a roadmap for the package around the fall holiday, and spent most evenings there re-factoring so that the unpacking of the formulas was uncoupled from the generation of the JAGS code.
The new architecture was incredibly easy to extend and then things went really fast. In particular, I looked a lot to brms for inspiration on the API. I wanted to make sure that the design could accommodate virtually endless oportunities.
Here we are!
Why “mcp”?
mcp was the first name I came up with. I like it because it means multiple things to me:
Multiple Change Points as in “more than one change point”
Multiple Change Points as in “multiple kinds of models and change points”.
MC for “Markov Chains” to hint at the underlying MCMC sampling. We could give the package the pet name “Markov Chainge Points”.
I think I would have renamed it to “rcp” or “cpr” (“Regression with change points”) if they weren’t taken. “changepoint” is also a great name that’s already taken.
By Sebastian Bergmann Tillner Jensen, Malene Klarborg Holst, Tine Randrup-Thomsen, Camilla Erfurt Brøchner, & Jonas Kristoffer Lindeløv (supervisor). Project conducted as part of the Psychology bachelor at Aalborg University, Denmark.
Can we frame learning situations in such a way that people actually improve their abilities outside the classroom? We believe that the answer could be yes. Following newer school trends in adopting visible learning, as proposed by Professor of Education John Hattie, we believe that an instruction which motivates the pupil to think outside the box and evaluate the general applicability of their skills might be the key in improving learning. But how do we grab this concept from rich real-life situations and move it into the lab?
The holy grail in all of teaching is the transfer of learning, i.e., using a narrow teaching material to achieve generalized effects. Transfer of learning was first introduced by Edward Thorndike, Father of Educational Psychology, in 1901 and after many years of research, it is still a hotly debated topic to what extent humans (and other animals) actually can transfer learning.
In 2008 Jaeggi and colleagues published an article in one extreme of this debate, suggesting the ultimate far transfer: training an N-back task led to large improvements in fluid intelligence. Not surprisingly, this attracted a lot of attention to the N-back task as a holy grail of transfer research – at least in the four years until several large RCTs failed to replicate the findings (Redick et al., 2013, Chooi & Thompson, 2012; see also recent meta-analyses by Melby-Lervåg, Redick & Hulme, 2016 and Soveri et al., 2017).
Put shortly, during the N-back task the participant is presented with a sequence of stimuli, and the task is to decide for each stimulus whether it is the same as the one presented N trials earlier. Try it out yourself: http://brainscale.net/dual-n-back/training.
Entering the lab
Using different versions of the N-back in a pretest-training-posttest design, we created a setup, which allowed us to utilize improvement as a measure of transfer. We split our participants into two identical groups – except we gave them different instructions before the training session: One group received an instruction, based on visible learning, to use the training to improve on the transfer tasks; and the other was directly instructed to improve as much as possible during the training.
Before revealing the shocking nature of the quad N-back, we first need to dig deeper into the N-back…
Are all N-backs the same?
If you have ever stumbled upon the N-back before, it has probably been used as a measure of working memory (WM). But does the N-back live up to the task of encapsulating the rich nature of WM? We say no…
Strong evidence points towards the fact that N-back does not transfer to other WM tasks (i.e. complex span, see Redick & Lindsey, 2013) since it primarily taps into updating and interference control.
But wait! There is more… Evidence points towards the notion that the N-back does not always transfer to other versions of itself!
Yep. That was pretty much our reaction…
Research on the holy grail of learning is primarily focusing on 2-backs or higher; meaning that updating and mental reallocation of stimuli is a given. But what if we reduce the amount of N to 1? (see Chen, Mitra & Schlaghecken, 2008).
Creating an N-back transfer spectrum
And now what we have all been waiting for… *drumroll*… The quad N-back! Assuming that transfer varies between different versions of the N-back we can change the number of stimuli used, the type of stimuli used as well as N to create a transfer spectrum ranging from near to far relative to the training task. Disclaimer: This has been done relatively blind-sighted, since we found little literature to lean on, but here we go anyways!
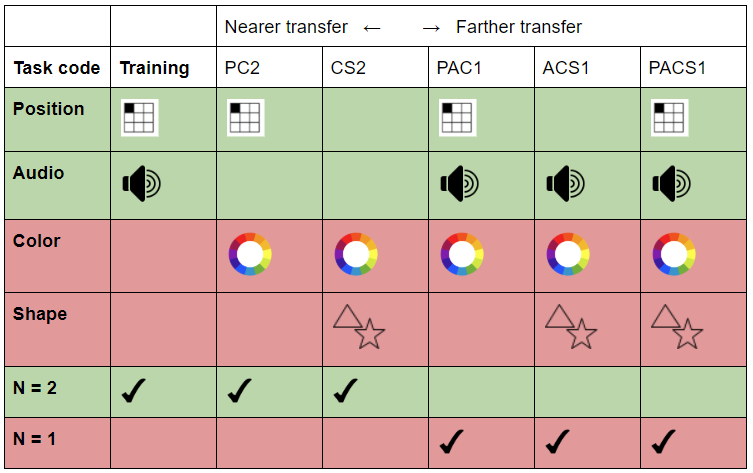
Our shot at a transfer spectrum is visualized on the table below, in which the “farness” is based on the number of stimuli similar to the training task – a dual 2-back with position and audio. Pre- and posttest consisted of five different N-backs as can be seen in the table below.
A visualization of our attempted transfer spectrum. GREEN indicates stimuli identical to the training task. RED indicates new stimuli.
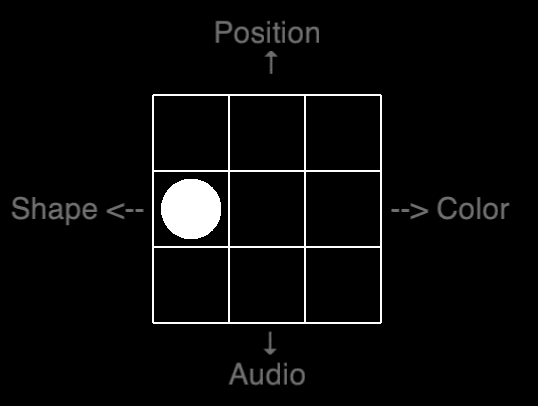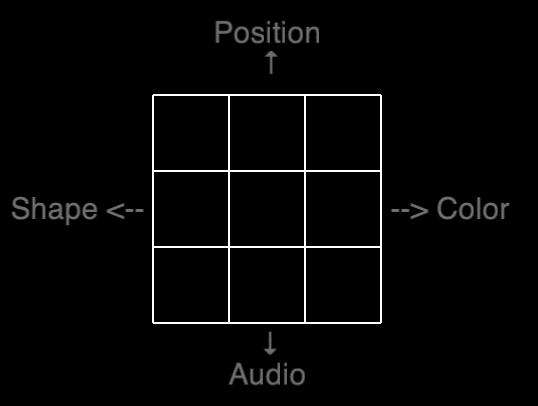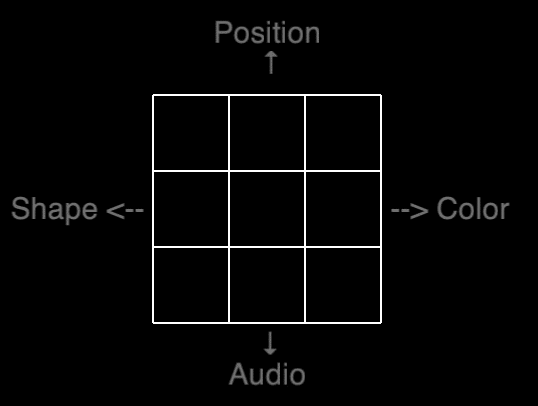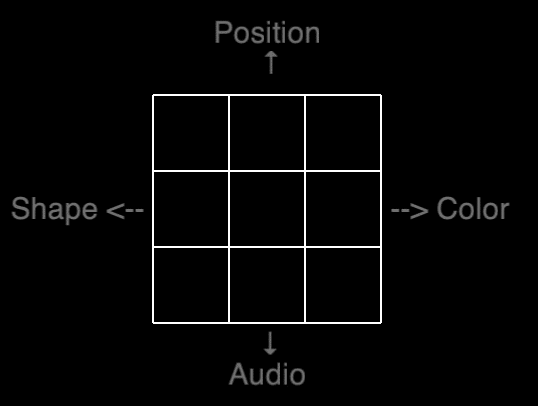
Now you may wonder what a quad 1-back looks like. Lo and behold the actually-not-so-terrifying abomination, which is the quad 1-back. Press the four arrows when the feature is identical to the previous stimuli:
FUN FACT: Our participants actually performed better on the quad 1-back tasks than on the dual 2-back tasks, indicating that we in the future quite ethically can expose our participants to even more stimuli *maniacal laughter*.
If you’re interested in knowing what our data showed, feel free to read the results-section below, and if you’re really, really interested, you can download our full report (in Danish – Google translate is your friend).
Results
We used the BayesFactor R package with default priors. Using default priors is generally not advisable, but this is a student project with a tight timeframe!
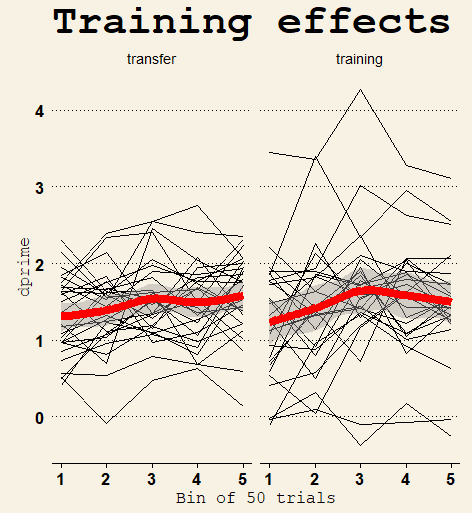
As expected, the improvement was quite small during the 10 minutes of training (Δd’ = 0.30 and 0.31 respectively, joint 95% CI [0.05, 0.59]) as revealed by linear regression on the time x instruction interaction. Surprisingly (to us at least), the evidence favored the model that participants who were instructed to focus on the transfer tasks improved just as much as participants who focused on improving on the training (BF01 = 5.1).
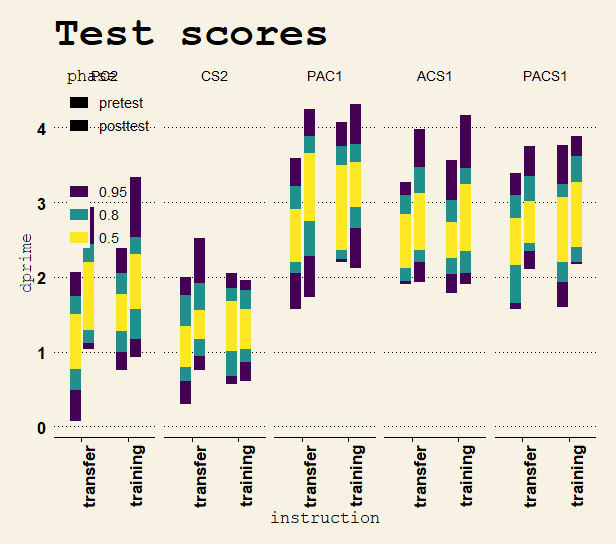
Participants who were instructed to focus on transfer had numerically superior improvements in the “nearer” part of the transfer spectrum, but the instruction x task x time interaction in an RM-ANOVA favored the model that the transfer instruction did not cause a superior (different) transfer effect (BF01 = 23.3).
Individual and mean d’ over time during training. There were 250 training trials in total, 50 in each bin on the x-axis. Distribution of d-prime scores at pretest and posttest. d’ was greater for 1-back than for 2-back.
Limitations
We used the same test order in pre- and posttest for all participants, likely imposing order effects (which is basically transfer occurring in between tasks in the pretest). As a solution for future studies we suggest to counterbalance the order of task 1 to 5 in pre- and posttest. Another solution could be to create a baseline score in practice-tasks before continuing to the pretest.
Secondly, our transfer spectrum is not self-evidently correctly ordered. We did not take the difference between 1- and 2-backs into consideration when creating the transfer spectrum, as to why we propose future research to choose between the two. One could focus on only the amount of stimuli instead of both the number of stimuli and N-backs.
Thirdly, we did not have enough participants to establish the desired power level. Further, the training session was probably too short. The obvious solution is to collect more participants and prolong the training.